TL; DR 如果你想使用和我一样的 Voxtype 体验,不妨直接参考我的博客!这一节直接记录了安装方法和使用方法!
演示视频:
最近看到了 Typeless,号称是最好用的语音输入法。其主要特色是精准的语音识别,和基于 LLM 的强大的文本后处理(如删除语气词,添加标点等功能),还有用语音快速编辑文本的能力。有人向我推荐过这个软件,并声称其极大地提高了效率,用 Typeless 写 prompt 可以进一步提高 coding agent 效率。
3/1/2026 UPDATE 体验了一下,确实如此!Typeless 相当好用。推荐所有同学都去试一试!
可惜它现在仅支持 macOS, Windows, iOS, Android 四个平台,而我用的是 Linux。
昨天试了试在 linux 搭了一个本地的 Voxtype,用 OpenAI whisper 做识别,本地跑个 qwen2.5:1.5b 做后处理,好像效果也不错。给大家推荐一下。
voxtype 配置过程
voxtype 官网:https://voxtype.io。上面有详细的安装过程,以及使用视频。默认使用的是 base.en 这个 OpenAI whisper 模型,我会切到 base 模型,并添加识别中文的功能。默认未开启文本后处理,我使用 ollama 运行 qwen2.5:1.5b 进行后处理。所有模型均在本地运行。
我的本机配置如下:
$ fastfetch -l none --pipe
OS: Arch Linux x86_64
Host: HP ProBook 440 14 inch G10 Notebook PC
Kernel: Linux 6.18.9-arch1-2
Uptime: 10 hours, 41 mins
Packages: 2302 (pacman)
Shell: zsh 5.9
Display (AUO2FA6): 1920x1080 in 14", 60 Hz [Built-in] *
Display (Xiaomi Corporation 24"): 1920x1080 in 24", 60 Hz [External]
DE: GNOME 49.4
WM: Mutter (Wayland)
WM Theme: Marble-purple-dark
Theme: Adwaita [GTK2/3/4]
Icons: kora [GTK2/3/4]
Font: Noto Sans CJK SC (11pt) [GTK2/3/4]
Cursor: default (24px)
Terminal: kitty 0.45.0
Terminal Font: JetBrainsMonoNF-Regular (14pt)
CPU: 13th Gen Intel(R) Core(TM) i5-1340P (16) @ 4.60 GHz
GPU: Intel Iris Xe Graphics @ 1.45 GHz [Integrated]
Memory: 7.76 GiB / 15.25 GiB (51%)
Swap: 1.57 GiB / 16.00 GiB (10%)
Disk (/): 428.43 GiB / 936.87 GiB (46%) - btrfs
Battery (Primary): 98% [AC Connected]
Locale: en_US.UTF-8
运行这两个模型的速度适中(大约等待 5~10s),且内存占用不高。
以下是我的配置(~/.config/voxtype/config.toml)
# Voxtype Configuration
#
# Location: ~/.config/voxtype/config.toml
# All settings can be overridden via CLI flags
# State file for external integrations (Waybar, polybar, etc.)
# Use "auto" for default location ($XDG_RUNTIME_DIR/voxtype/state),
# a custom path, or "disabled" to turn off. The daemon writes state
# ("idle", "recording", "transcribing") to this file whenever it changes.
# Required for `voxtype record toggle` and `voxtype status` commands.
state_file = "auto"
[hotkey]
# Key to hold for push-to-talk
# Common choices: SCROLLLOCK, PAUSE, RIGHTALT, F13-F24
# Use `evtest` to find key names for your keyboard
key = "SCROLLLOCK"
# Optional modifier keys that must also be held
# Example: modifiers = ["LEFTCTRL", "LEFTALT"]
modifiers = []
# Activation mode: "push_to_talk" or "toggle"
# - push_to_talk: Hold hotkey to record, release to transcribe (default)
# - toggle: Press hotkey once to start recording, press again to stop
# mode = "push_to_talk"
# Enable built-in hotkey detection (default: true)
# Set to false when using compositor keybindings (Hyprland, Sway) instead
# When disabled, use `voxtype record start/stop/toggle` to control recording
# enabled = true
# Modifier key to select secondary model (evdev input mode only)
# When held while pressing the hotkey, uses whisper.secondary_model instead
# Example: model_modifier = "LEFTSHIFT" # Shift+hotkey uses secondary model
# model_modifier = "LEFTSHIFT"
[audio]
# Audio input device ("default" uses system default)
# List devices with: pactl list sources short
device = "default"
# Sample rate in Hz (whisper expects 16000)
sample_rate = 16000
# Maximum recording duration in seconds (safety limit)
max_duration_secs = 60
# [audio.feedback]
# Enable audio feedback sounds (beeps when recording starts/stops)
# enabled = true
#
# Sound theme: "default", "subtle", "mechanical", or path to custom theme directory
# theme = "default"
#
# Volume level (0.0 to 1.0)
# volume = 0.7
[whisper]
# Transcription backend: "local" or "remote"
# - local: Use whisper.cpp locally (default)
# - remote: Send audio to a remote whisper.cpp server or OpenAI-compatible API
# backend = "local"
# Model to use for transcription (local backend)
# Options: tiny, tiny.en, base, base.en, small, small.en, medium, medium.en, large-v3, large-v3-turbo
# .en models are English-only but faster and more accurate for English
# large-v3-turbo is faster than large-v3 with minimal accuracy loss (recommended for GPU)
# Or provide absolute path to a custom .bin model file
model = "small"
# Language for transcription
# Options:
# - Single language: "en", "fr", "de", etc.
# - Auto-detect all: "auto"
# - Constrained auto-detect: ["en", "fr"] (detects from allowed set only)
# The array form helps with multilingual users where Whisper might misdetect
# the language, especially for short sentences.
# See: https://github.com/openai/whisper#available-models-and-languages
language = ["en", "zh"]
# Translate non-English speech to English
translate = false
# Number of CPU threads for inference (omit for auto-detection)
# threads = 4
# Initial prompt to provide context for transcription
# Use this to hint at terminology, proper nouns, or formatting conventions.
# Example: "Technical discussion about Rust, TypeScript, and Kubernetes."
# initial_prompt = ""
# --- Multi-model settings ---
#
# Secondary model for difficult audio (used with hotkey.model_modifier or CLI --model)
# secondary_model = "large-v3-turbo"
#
# List of available models that can be requested via CLI --model flag
# available_models = ["large-v3-turbo", "medium.en"]
#
# Maximum models to keep loaded in memory (LRU eviction when exceeded)
# Default: 2 (primary + one secondary). Only applies when gpu_isolation = false.
# max_loaded_models = 2
#
# Seconds before unloading idle secondary models (0 = never auto-unload)
# Default: 300 (5 minutes). Only applies when gpu_isolation = false.
# cold_model_timeout_secs = 300
# --- Eager processing settings ---
#
# Enable eager input processing (transcribe chunks while recording continues)
# Reduces perceived latency on slower machines by processing audio in parallel.
# eager_processing = false
#
# Duration of each audio chunk in seconds (default: 5.0)
# eager_chunk_secs = 5.0
#
# Overlap between chunks in seconds (helps catch words at boundaries, default: 0.5)
# eager_overlap_secs = 0.5
# --- Remote backend settings (used when backend = "remote") ---
#
# Remote server endpoint URL (required for remote backend)
# Examples:
# - whisper.cpp server: "http://192.168.1.100:8080"
# - OpenAI API: "https://api.openai.com"
# remote_endpoint = "http://192.168.1.100:8080"
#
# Model name to send to remote server (default: "whisper-1")
# remote_model = "whisper-1"
#
# API key for remote server (optional, or use VOXTYPE_WHISPER_API_KEY env var)
# remote_api_key = ""
#
# Timeout for remote requests in seconds (default: 30)
# remote_timeout_secs = 30
[output]
# Primary output mode: "type" or "clipboard"
# - type: Simulates keyboard input at cursor position (requires ydotool)
# - clipboard: Copies text to clipboard (requires wl-copy)
mode = "type"
# Fall back to clipboard if typing fails
fallback_to_clipboard = true
# Custom driver order for type mode (optional)
# Default order: wtype -> dotool -> ydotool -> clipboard
# Customize to prefer a specific driver or change the fallback order.
# Available drivers: wtype, dotool, ydotool, clipboard
# Example: prefer ydotool over dotool:
# driver_order = ["wtype", "ydotool", "dotool", "clipboard"]
# Example: use only ydotool, no fallback:
# driver_order = ["ydotool"]
# driver_order = ["wtype", "dotool", "ydotool", "clipboard"]
# Delay between typed characters in milliseconds
# 0 = fastest possible, increase if characters are dropped
type_delay_ms = 0
# Automatically submit (send Enter key) after outputting transcribed text
# Useful for chat applications, command lines, or forms where you want
# to auto-submit after dictation
# auto_submit = true
# Convert newlines to Shift+Enter instead of regular Enter
# Useful for applications where Enter submits (e.g., Cursor IDE, Slack, Discord)
# shift_enter_newlines = false
# Pre/post output hooks (optional)
# Commands to run before and after typing output. Useful for compositor integration.
# Example: Block modifier keys during typing with Hyprland submap:
# pre_output_command = "hyprctl dispatch submap voxtype_suppress"
# post_output_command = "hyprctl dispatch submap reset"
# See troubleshooting docs for the required Hyprland submap configuration.
# Post-processing command (optional)
# Pipe transcribed text through an external command for cleanup before output.
# The command receives text on stdin and outputs processed text on stdout.
# Useful for LLM-based text cleanup, grammar correction, filler word removal.
# On any failure (timeout, error), falls back to original transcription.
#
[output.post_process]
command = "(echo -n '<|system|>对用户输入的句子,仅做以下修饰 1.添加适当的标点 2.去除重复的词语和语气词。**不要做其他任何事情(严禁换词、删词、改变语序、改变人称代词)**。<|user|>'; cat; echo '<|assistant|>') | ollama run qwen2.5:1.5b | opencc -c t2s.json"
timeout_ms = 30000 # 30 second timeout (generous for LLM)
[output.notification]
# Show notification when recording starts (hotkey pressed)
on_recording_start = false
# Show notification when recording stops (transcription beginning)
on_recording_stop = false
# Show notification with transcribed text after transcription completes
on_transcription = true
# [text]
# Text processing options (word replacements, spoken punctuation)
#
# Enable spoken punctuation conversion (e.g., say "period" to get ".")
# spoken_punctuation = false
#
# Custom word replacements (case-insensitive)
# replacements = { "vox type" = "voxtype" }
# [vad]
# Voice Activity Detection - filters silence-only recordings
# Prevents Whisper hallucinations on silent audio
#
# enabled = false # Enable VAD (off by default)
# threshold = 0.5 # 0.0 = sensitive, 1.0 = aggressive
# min_speech_duration_ms = 100 # Minimum speech required
# [status]
# Status display icons for Waybar/tray integrations
#
# Icon theme (or path to custom theme file):
# Font-based (require specific fonts):
# - "emoji" - Default emoji icons (🎙️ 🎤 ⏳)
# - "nerd-font" - Nerd Font icons (requires Nerd Font)
# - "material" - Material Design Icons (requires MDI font)
# - "phosphor" - Phosphor Icons (requires Phosphor font)
# - "codicons" - VS Code icons (requires Codicons font)
# - "omarchy" - Omarchy distro icons
# Universal (no special fonts needed):
# - "minimal" - Simple Unicode (○ ● ◐ ×)
# - "dots" - Geometric shapes (◯ ⬤ ◔ ◌)
# - "arrows" - Media player style (▶ ● ↻ ■)
# - "text" - Plain text ([MIC] [REC] [...] [OFF])
# icon_theme = "emoji"
#
# Per-state icon overrides (optional, takes precedence over theme)
# [status.icons]
# idle = "🎙️"
# recording = "🎤"
# transcribing = "⏳"
# stopped = ""
# [profiles]
# Named profiles for context-specific post-processing
# Use with: voxtype record start --profile slack
#
# [profiles.slack]
# post_process_command = "ollama run llama3.2:1b 'Format for Slack...'"
#
# [profiles.code]
# post_process_command = "ollama run llama3.2:1b 'Format as code comment...'"
# output_mode = "clipboard"
2/28/2026 UPDATE 我改进了Voxtype,使其能通过按键选择不同复杂度的LLM后处理功能,并推荐使用性价比高的DeepSeek API替代本地模型。
3/1/2026 UPDATE 我修改了voxtype以同时使用Paraformer-zh和Whisper模型,分别优化中英文识别。
3/1/2026 UPDATE 我为我的voxtype分支添加了语音编辑文本功能,用户可通过复制文本、使用热键进行语音指令输入,最终将处理结果粘贴使用。
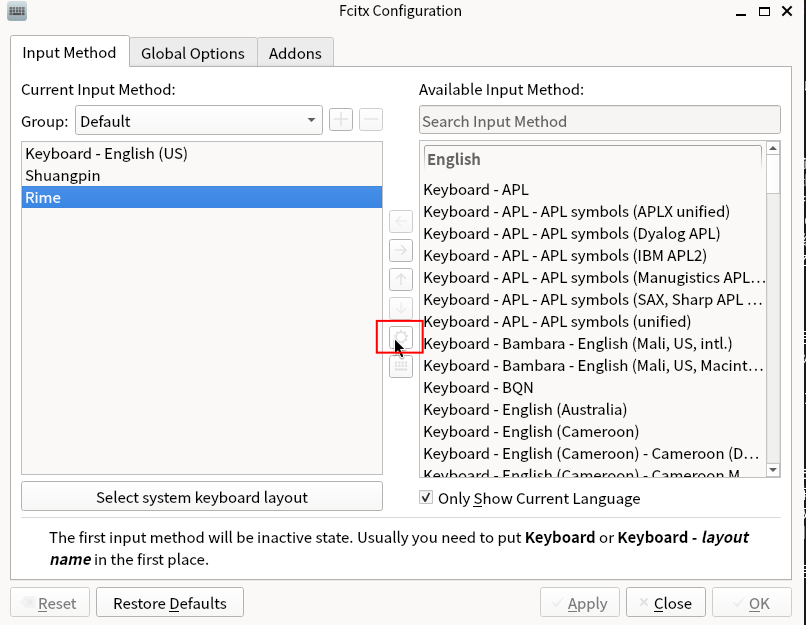
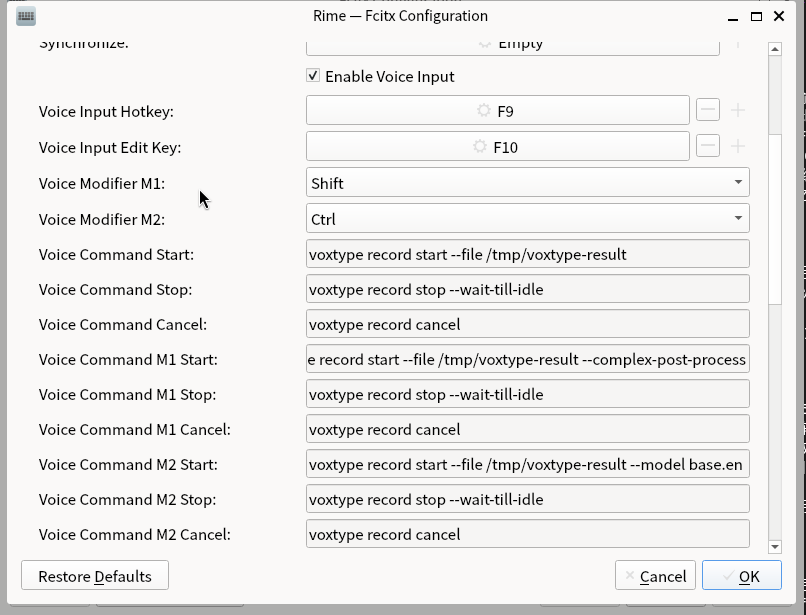
3/2/2026 UPDATE 我魔改了Fcitx5的Rime输入框架,添加了可通过按键开关语音输入的功能,使体验更接近Typeless。
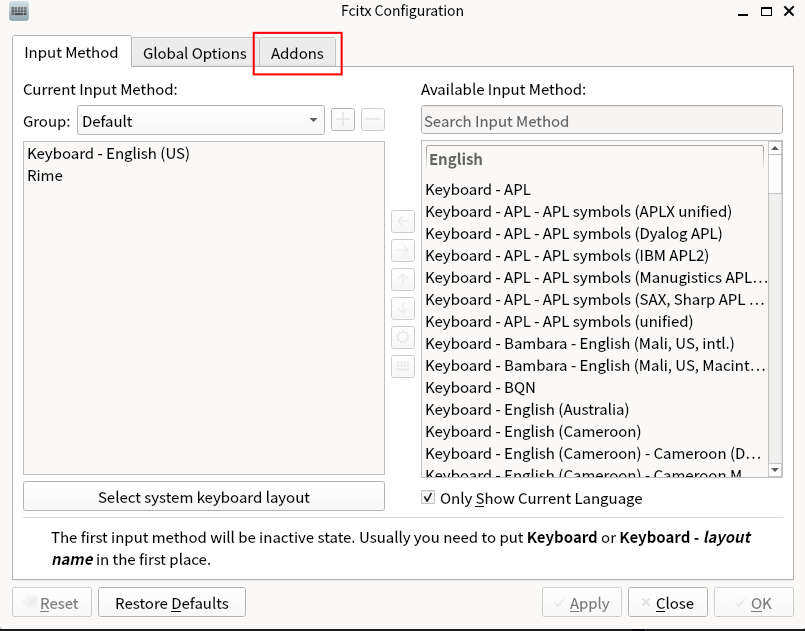
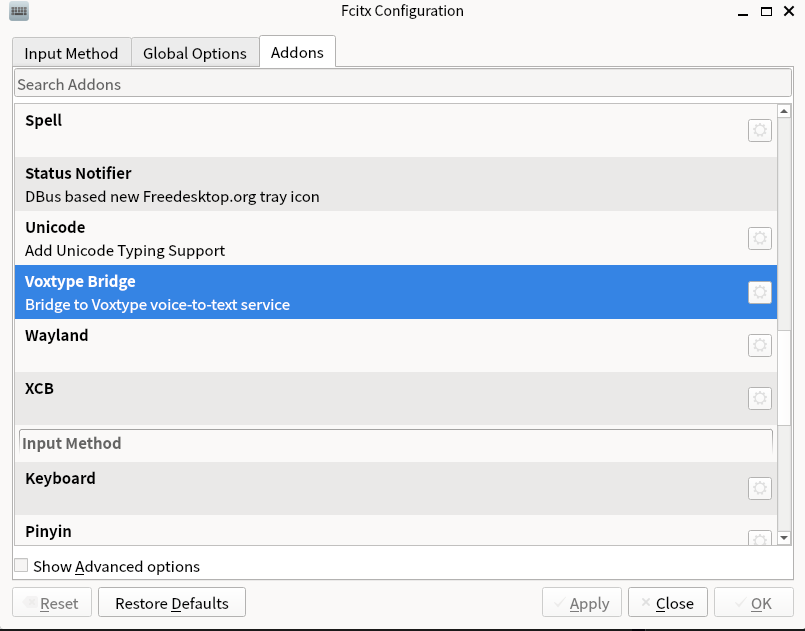
3/3/2026 UPDATE 重写了fcitx5部分,现直接使用其addon并支持任意fcitx5输入法,新增"push_to_talk"按键录音模式,并优化了可打断的"处理中"状态。